Running LLM Checkpointing Benchmark using DLIO
Author
Huihuo Zheng, Argonne National Laboratory
Email: huihuo.zheng@anl.gov
Date: February 7, 2025
Overview
In LLM training, I/O occurs in two phases:
- Reading the dataset for training – Similar to traditional deep learning training, where computation dominates, making dataset reading less intensive.
- Checkpointing intermediate results – More significant due to the large size of LLM models, often involving writes in the order of TBs. Large-scale training requires storage that supports high concurrency.
We have integrated this workload into the DLIO codebase, allowing users to benchmark checkpoint performance for different LLM models. We also plan to include this checkpointing benchmark in MLPerf Storage Benchmark v2.0.
Running the Benchmark
Development work is available in this PR (to be merged soon):
GitHub Pull Request
Commands to Run the Benchmark
git clone -b feature/transformer git@github.com:argonne-lcf/dlio_benchmark.git
cd dlio_benchmark
# Ensure Python 3.10 is used if issues arise with Python 3.12
python3 -m pip install --upgrade pip
CC=mpicc CXX=mpicxx python -m pip install -r ./requirements.txt
# Remove nvidia-dali-* *pydftracer from requirements.txt if they cause issues
export PYTHONPATH=$PWD:$PYTHONPATH
By default:
- Checkpoint files are saved in
./checkpoints/{workload}/ - Log files are saved in
hydra_log/{workload}/
Example Execution
mpiexec -np 128 --ppn 8 --cpu-bind list:xxxxx python3 dlio_benchmark/main.py workload=llama_70b_zero3
mpiexec -np 128 --ppn 8 --cpu-bind list:xxxxx python3 dlio_benchmark/main.py workload=llama_7b_zero3
mpiexec -np 128 --ppn 8 --cpu-bind list:xxxxx python3 dlio_benchmark/main.py workload=llama_405b
mpiexec -np 128 --ppn 8 --cpu-bind list:xxxxx python3 dlio_benchmark/main.py workload=llama_1t
Benchmark Results
Results are stored in summary.json, which includes key metrics:
{
"num_accelerators": 1024,
"num_hosts": 128,
"hostname": "x1000c0s5b1n0",
"metric": {
"checkpoint_io_mean_GB_per_second": 132.316,
"checkpoint_io_stdev_GB_per_second": 5.972,
"checkpoint_duration_mean_seconds": 7.897,
"checkpoint_duration_stdev_seconds": 0.355,
"checkpoint_size_GB": 1042.846
}
}
per_epoch_stats.json provides per-checkpoint statistics, including timestamps and throughput.
Model Configurations
| Model | Hidden Dimension | Num Layers | FFN Size | Vocab Size | Checkpoint Size | # GPUs |
|---|---|---|---|---|---|---|
| Llama 7B | 4096 | 32 | 11008 | 32k | 88GB | 1 x 1 x 16 |
| Llama 8B | 4096 | 32 | 11008 | 128k | 104GB | 1 x 1 x 16 |
| Llama 70B | 8192 | 80 | 28672 | 128k | 1.1TB | 8 x 4 x DP? |
| Llama 405B | 16384 | 126 | 53248 | 128k | 6TB | 8 x 16 x 128 |
| Llama 1T | 25872 | 128 | 98304 | 128k | 17TB | 8 x 64 x DP? |
Pre-configured YAML files for different transformer models (Llama 7B, 70B, 405B, 1T) can be found at:
GitHub Config Files
Example Configuration
model:
name: llama_70b
type: transformer
model_size: 30102
num_layers: 80
parallelism:
tensor: 8
pipeline: 1
zero_stage: 3
transformer:
vocab_size: 128000
hidden_size: 8192
ffn_hidden_size: 28672
Performance Scaling
For benchmarking:
- Fix TP (Tensor Parallelism) and PP (Pipeline Parallelism) values
- Increase total GPUs (must be a multiple of TP * PP)
Expected Behavior
- Zero 3 generally has better I/O performance than Zero 1 due to optimizer state sharding.
- Llama_7b_zero3 should outperform llama_7b in throughput.
- Increasing data parallel instances improves I/O throughput.
System Requirements
To run benchmarks, ensure memory capacity is sufficient:
- Zero 3:
Checkpoint_size / num_hosts - Zero 1:
model_size / pp + opt_size / num_hosts - Recommended: At least 256 GB memory per host
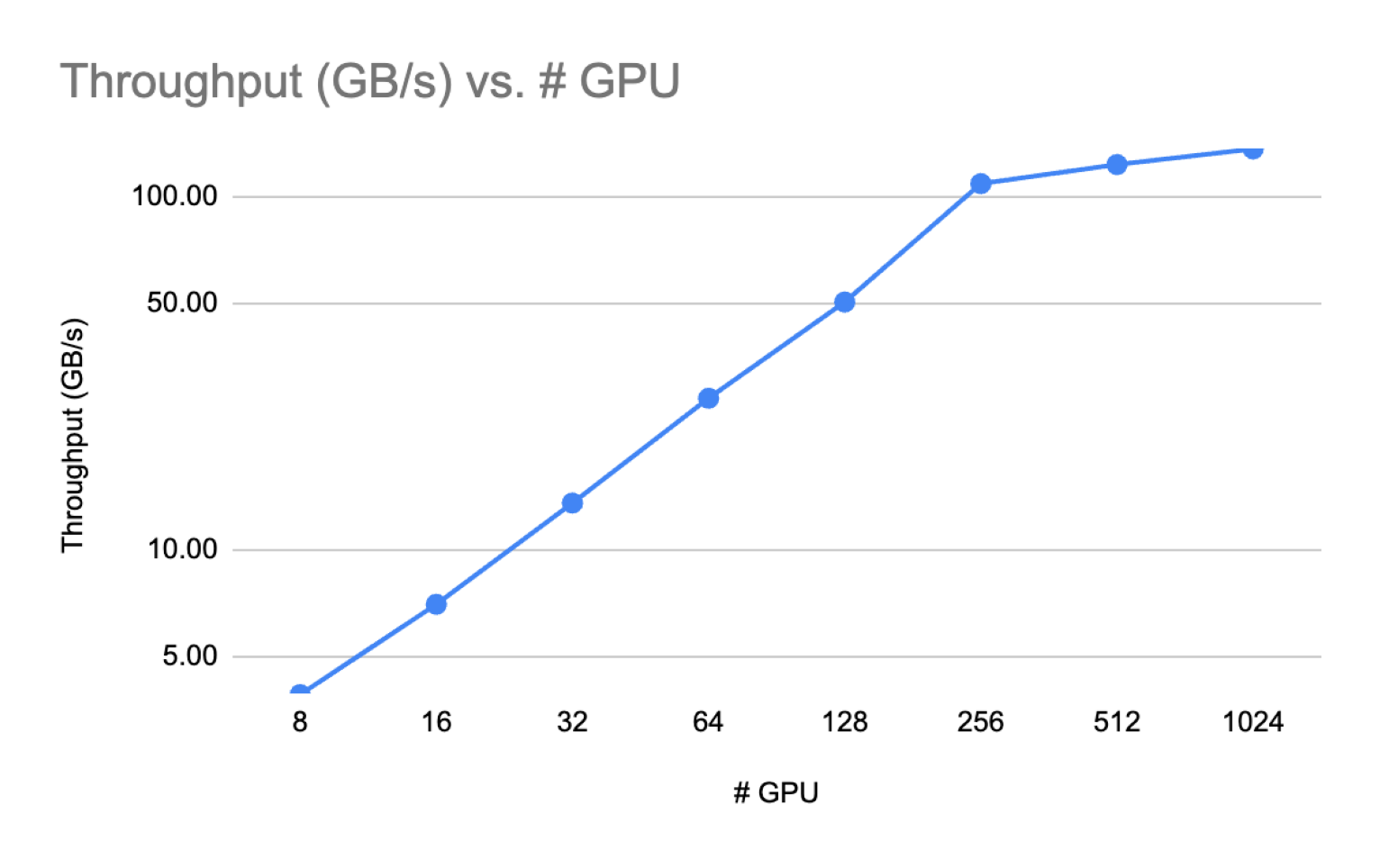
Preliminary results on an ALCF system for llama_7b
As we can see that the throughput increases as we increase the number of MPI processes. In this case, 8 GPU per node is used. The results here were obtained with running the code out of the box. I purposely omitted the setup details.
{kind=link}